TL;DR Travis prepares a solution to easily upload files produced while
running tests to any external storage service. If you want to test it,
you can go straight to install instructions.
Travis is already very good at running your tests, but we feel that we can
do much better job with things that happen after the tests have
finished running. First step in this direction is what we call build artifacts.
Artifacts are files which are produced while running the tests. It may be
compiled version of a library, screenshots done while running your tests in the browser
or logs that can help with debugging test failures.
How to use?
We chose to start with something very simple, so travis-artifacts
is just a simple gem that is not built into travis architecture in any way.
In order to use artifacts you need to do a couple steps:
At this point we support only s3, so you need s3 account and credentials. After grabbing the
information from your account, you need to add it to .travis.yml using 4 env variables:
ARTIFACTS_S3_BUCKET
ARTIFACTS_AWS_REGION - the default is us-east-1
ARTIFACTS_AWS_ACCESS_KEY_ID
ARTIFACTS_AWS_SECRET_ACCESS_KEY
Last two vars should be kept secret, so you should encrypt them using travis gem, just like this:
Next thing is to install travis-artifacts gem in before_script stage,
simply add this to your .travis.yml:
before_script:
- "gem install travis-artifacts"
And finally we can add lines that will upload your files:
after_script:
- "travis-artifacts upload --path logs --path a/long/nested/path:short_alias"
after_failure: # this will of course run only on failure
- "travis-artifacts upload --path debug/debug.log"
after_success: # and this only on success
- "travis-artifacts upload --path build/build.tar.gz"
The default path to save files is “artifacts//”,
but you can customize it with --target-path option, for example:
In short future we would like to extend it with more providers and features, as well
as listen to your ideas, feedback and specific use cases. Please let us know what are
your thoughts on this topic.
Why don’t we use .travis.yml?
You may be wondering why we chose to create artifacts as a simple script rather than
addition to .travis.yml. At first this was my idea, but frankly speaking .travis.yml
is getting more and more complex, so we want to test new ideas without touching .travis.yml
format and then decide how to handle it in config, when we have more information on usage.
A bit longer story
When you run tests on travis, you can run any code in a various stages of test
execution, so obviously you could use your own scripts to upload build artifacts
to s3, but unless you have really specific needs, you’re probably reinventing the wheel.
When I started working on this task, at first my nature of “let’s build something
epic” took part and I prepared a proposal for a thin uploader script, which would
upload files to some kind of full blown proxy service, which would then process them
and upload to some kind of storage. I think it’s a quite good and
flexible idea, but when you’re short on manpower it becomes a bad one. If you add
the fact that currently we need to put a bit more work into architecture
improvements and that deploying code to workers is far from ideal, it becomes
even worse. So in order to allow test things and iterate quickly, the best way
is to come up with something that can be developed without any coupling
with the rest of the platform.
The other argument for going in such direction is that we’re not yet sure what will
we end up with. Maybe it will not evolve too much, but maybe based on use cases and
feedback we will change a lot in a way it works.
During the development of artifacts I wanted a way to run scripts regardless of test results.
There was no such hook, so I wanted to change after_script to behave that way.
I also exposed the TRAVIS_TEST_RESULT environment variable so you can check if tests failed
or passed at this point. This is a general purpose change in a way travis works and it will
be probably used in a lot of other use cases. That’s why it’s easy to justify such change
into one of the travis apps.
This is also a good way to deal with things in open source in general. Sometimes you would
like to make an addition to a library, which can’t be accepted. It may be something that
is a specific use case, which will not be used by a majority. It may be something that
is not yet well formed as an idea and needs testing or maybe maintainers are just not
interested in going that way. In such situations you can either fork the project, which
is not a good solution in the long run, because you need to maintain the fork, or you can extend
the library to allow you to plug in your extensions. I really like the latter approach, because
not only does it make the library more flexible, but it also makes your life easier.
Does this way of building thing have its drawbacks? Of course. For example, it will be hard
to save the list of uploaded files to the database and fetch it with the API. But maybe we won’t
need this feature at all? It’s better to check it as quickly as we can, than make assumptions
that can turn to be wrong.
I recently gave a presentation about Travis CI at Øredev. For this preparation, I sat down with our production database and ran a few aggregations. Our schema currently makes some of these not that easy, so most of the following numbers were pretty new to us, too.
Before you take a look at the graphs below, a word of warning: The data is not fully up to date (numbers are as of October 26).
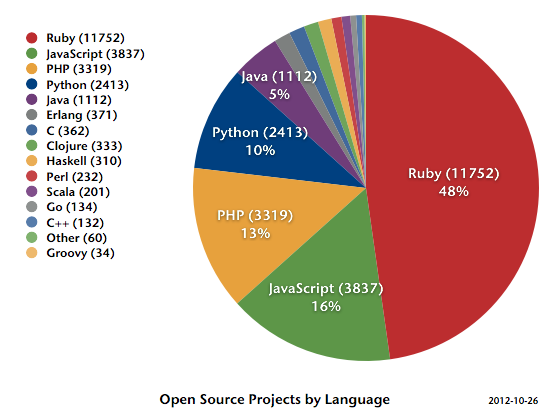
Projects and Activity
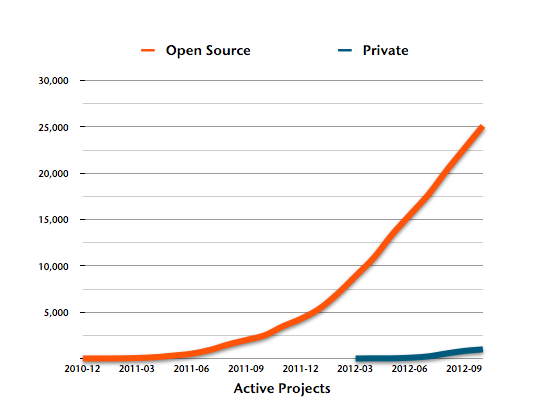
As you can see, our number of open source projects has crossed 25k about two months ago and is now steadily growing at about 90 new projects a day.
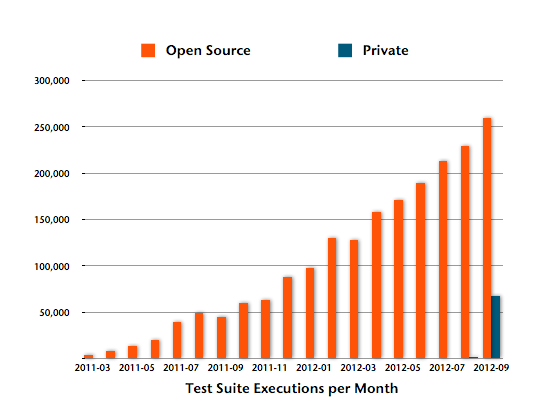
Interestingly, if you look at the open source vs private project ratio and then compare it with the overall system activity, it is easy to see that private projects are more active on average.
This actually makes sense if you think about it. Most open source projects are developed as side projects and see some commits now and then, whereas private projects often have a team of full time developers behind it.
For instance, by far the most active OSS project on Travis CI is Rails with more than 5500 builds. While Rails has been using Travis CI for nearly 1.5 years now, we saw private projects cross that number in no time.
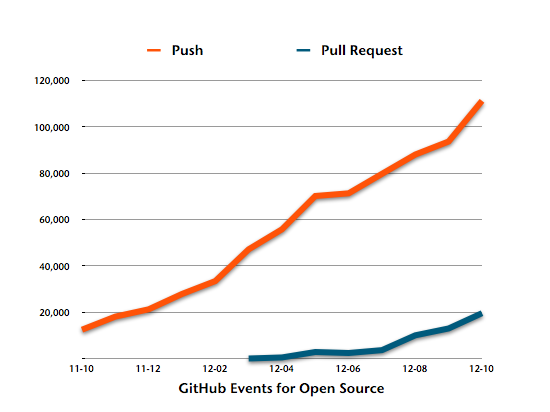
Push vs. Pull Requests
Here is one thing we didn’t expect. Look at pull requests compared to normal pushes for open source projects:
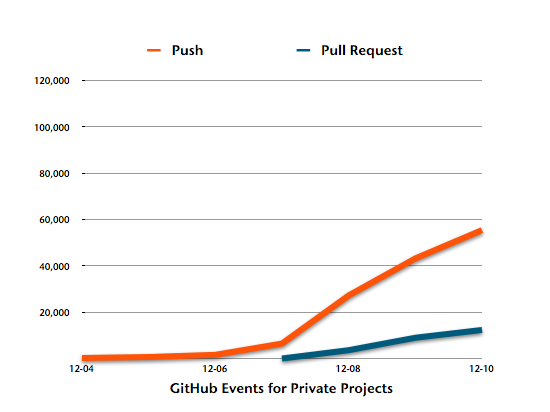
We expected the ratio to be different for private projects. And it indeed is, but exactly not the way we would have guessed.
I would have thought pull requests would be less common for private projects. Turns out, the vast majority of private projects seem to embrace feature branches and use pull requests for code review. Way to go!
Programming Languages
If you look at the distribution of programming languages on Travis CI, you easily see that it’s while Ruby is still the most used language, we now have more projects not using Ruby than we have projects using it.
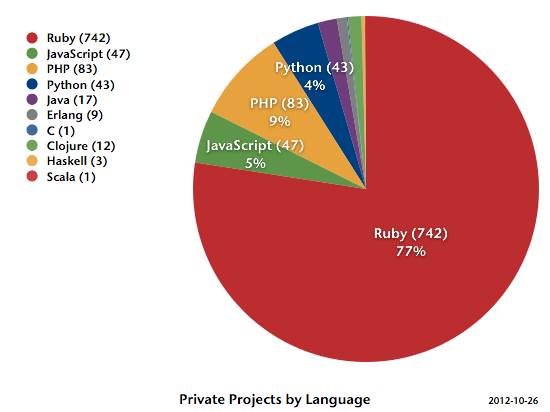
And for private projects, more than 75% are Ruby. Both is actually to be expected. While Travis CI is general purpose, it came from the Ruby community, where it matured to the de facto standard for open source projects. And most of the companies donating to our crowd funding campaign are working with Ruby.
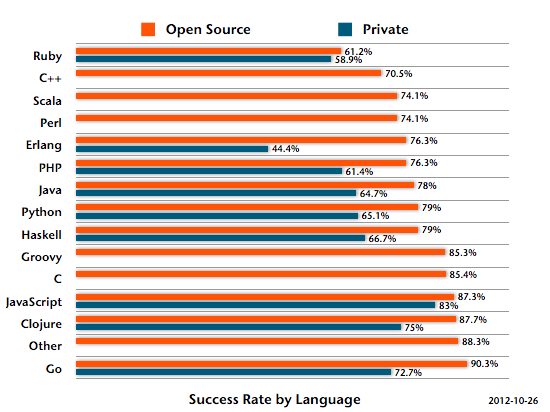
One last thing I did, and I’m not sure it was a wise thing to do: I looked at whether the last build of each project was failing or passing, and then grouped that by language. That build could have been a pull request or feature branch, it does not necessarily reflect the master branch or project state.
I actually published this graph before the conference and it sparked much debate.
It’s also interesting to see that the open source success rate was always above the rate of private projects.
What’s next?
We really love stats. And, even though these stats are already pretty interesting, they are also somewhat basic.
If you love to see more stats, then we have some really good news for you: We have a group of HTW students currently playing with our data (of course all sensitive data removed and only for open source projects). They’re figuring out what conclusions to draw from it and how to best visualize that at the moment. More in due time.
We’ve had our share of issues over the last few months, and it’s time we give
you an update on what we’ve been doing about them.
The most important bit up front is that we’re breaking Travis down into more and
more small apps. We traditionally had one big component, called the hub, which
took care of pretty much everything: incoming build requests, processing builds,
processing build logs, processing notifications, synchronizing users with
GitHub.
As Travis grew, this single component broke our neck left and right. So we
decided to take it apart into several smaller apps, all with a strict focus on a
single concern. Let’s go through them one by one.
Logs
We made improvements to logs by breaking it out of the hub entirely. Processing
them runs in parallel so we can make sure we can keep up with the increasing log
volume.
To give you perspective, travis-ci.org handles about
1500 log updates per minute during peak hours, while
travis-ci.com has to handle 2500. In situations where our
log processing has temporarily backed up, it handled 4000 updates per minute.
While that only boils down to ~66 writes per second, our current data
model is bound to break down eventually as we scale up, as too much data needs
to be written with each write.
Needless to say, we’re far from done with improving log processing. They tend to
be the biggest factor in the data Travis processes. They also take up the vast
majority of data we store.
Even our current design doesn’t yet fully allow us to scale out horizontally.
Logs are currently kept in a single attribute per build job, which is far from
optimal. While we can do a good amount of writes there per second, we want to
move to a setup where we only keep log chunks around.
By breaking up logs as we store them, we remove the need for temporal ordering,
which is our biggest breaking point right now in log processing. We rely on the
order of the log messages to be processed, and that’s the bane for any
distributed system as it grows and needs to scale up. By removing that need we
can process logs in parallel regardless of the order in which messages arrive.
The write process leaves reassembling and vacuuming log chunks into full log
files to other processes, making sure that it gets the highest throughput
possible when storing them.
Fixing this is highest on our list of things to tackle next, and we’ll keep you
posted.
Notifications
Build notifications like email, Campfire, IRC, etc. have been moved to their
own, isolated app. It has no contact with our main database at all anymore, it
just handles payloads and triggers the notifications that notify you of build
results.
As notifications are exclusively bound by I/O, it makes a lot of sense to allow
them to run multi-threaded.
Currently travis-tasks is still bound by a shared Redis instance, something
we’re considering improving in the future, to decouple it even more from the
other apps.
Build Requests and User Sync
Handling build requests is also mostly a matter of I/O, as we fetch data from
GitHub and create builds in the database. Same is true for user sync, a part of
Travis that has been rather unstable before introducing this component, aptly
called gatekeeper.
Both parts of Travis now also run on Sidekiq, which allows us to not only run a
lot more build requests in parallel, across multiple processes, it also allows
us to make use of some of Sidekiq’s neat features, like retries with exponential
back-off.
Should a build request temporarily fail because a glitch in the GitHub API,
Sidekiq tries again a few seconds later, expanding the interval between retries
over time. It’s a very handy feature for our use case.
Even if there’s a prolonged issue with the GitHub API, we can make sure that we
don’t lose any build requests because of it.
Postgres
Both Travis platforms are now running off a pair of Heroku Postgres
Fugu instances, with a master and a follower each,
allowing us to do emergency failovers if necessary. We had to make use of this
neat feature a few times unfortunately, as we hit a Postgres bug whose root cause
has yet to be fully determined.
As Travis grew, the write latencies on the smaller instances were suboptimal,
slowing down log processing and accessing the data.
On the new instances, our write latencies are commonly around 20-50ms in the
95th percentile, which is pretty good for our use case currently.
Lots of little apps!
The future of Travis’ architecture is in lots of smaller apps, that’s for
sure. Breaking out separate concerns into their own apps has the benefit of
being able to improve, grow and scale them independent of each other. While we
still have lots of work to do there, but the recent changes have shown us the
direction we’re heading into.
Another big hurdle we had along the way was managing dependencies, so we started
grouping our core dependencies by concern so that we can start breaking that
apart into smaller dependencies based on concerns instead of layers.
All of the above apps are now running on JRuby 1.7. Being able to process things
in parallel is a big benefit for us, and JRuby’s native threading is a natural
fit there. Thanks to Heroku’s easy application deployment model,
we’ve been able to iterate on this and set up new apps quickly.
Travis is still growing, and making sure both platforms are running as smoothly
as possible is our biggest priority. It’s still a lot of work, so please bear
with us.
We have other infrastructure changes planned, but more on those in another blog
post.